








如何在 Crawl4AI 中通过 CapSolver 集成解决 reCAPTCHA v2

Emma Foster
Machine Learning Engineer
21-Oct-2025

“我不是机器人”复选框是网站防止机器人流量和自动化滥用的重要防御机制。虽然对于安全至关重要,但它常常给合法的网络爬虫和数据提取操作带来重大挑战。对于依赖网络自动化的开发人员和企业来说,高效、自动化的CAPTCHA解决解决方案变得至关重要。
本文深入探讨了Crawl4AI(一个先进的网络爬虫)与CapSolver(领先的CAPTCHA解决服务)的集成,特别是解决reCAPTCHA v2。我们将探讨基于API和浏览器扩展的集成方法,提供详细的代码示例和解释,帮助您实现无缝、不间断的网络数据收集。
理解reCAPTCHA v2及其挑战
reCAPTCHA v2要求用户点击复选框,有时还需要完成图像挑战,以证明他们是人类。对于像网络爬虫这样的自动化系统,这种交互元素会暂停爬取过程,需要手动干预或复杂的绕过技术。如果没有有效的解决方案,数据收集就会变得低效、不稳定且成本高昂。
CapSolver通过利用先进的AI算法,为reCAPTCHA v2提供高准确性、快速响应的解决方案。当与Crawl4AI集成时,它将一个重大障碍转化为一个流畅的自动化步骤,确保您的网络自动化任务保持流畅和高效。
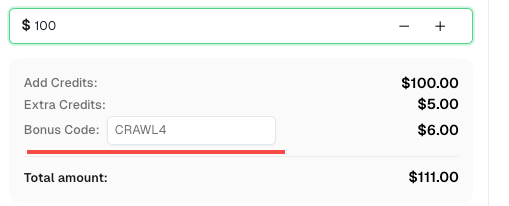
💡 Crawl4AI集成用户的专属优惠:
为了庆祝此次集成,我们为所有通过本教程注册的CapSolver用户提供了专属的 6% 优惠码 —CRAWL4。
只需在仪表板中充值时输入该代码,即可立即获得 额外6%的信用额度。
集成方法1:CapSolver API 与 Crawl4AI 集成
API 集成方法提供了细粒度的控制,通常因其灵活性和精确性而被推荐。它涉及使用 Crawl4AI 的 js_code 功能,将从 CapSolver 获取的 CAPTCHA 令牌直接注入目标网页。
工作原理:
- 导航到 CAPTCHA 页面: Crawl4AI 按照正常方式访问目标网页。
- 获取令牌: 在您的 Python 脚本中,使用 CapSolver 的 SDK 调用其 API,传递必要的参数如
siteKey和websiteURL,以获取gRecaptchaResponse令牌。 - 注入令牌: 使用 Crawl4AI 的
js_code参数在CrawlerRunConfig中注入获取到的令牌到页面上的g-recaptcha-response文本区域元素。 - 继续操作: 在成功注入令牌后,Crawl4AI 可以继续后续操作,如表单提交或点击,有效绕过 reCAPTCHA。
示例代码:reCAPTCHA v2 的 API 集成
以下 Python 代码演示了如何将 CapSolver 的 API 与 Crawl4AI 集成以解决 reCAPTCHA v2。此示例针对 reCAPTCHA v2 复选框演示页面。
python
import asyncio
import capsolver
from crawl4ai import *
# TODO: 设置您的配置
api_key = "CAP-xxxxxxxxxxxxxxxxxxxxx" # 您的 CapSolver API 密钥
site_key = "6LfW6wATAAAAAHLqO2pb8bDBahxlMxNdo9g947u9" # 您的目标网站的 siteKey
site_url = "https://recaptcha-demo.appspot.com/recaptcha-v2-checkbox.php" # 您的目标网站的页面 URL
captcha_type = "ReCaptchaV2TaskProxyLess" # 您的目标 CAPTCHA 类型
capsolver.api_key = api_key
async def main():
browser_config = BrowserConfig(
verbose=True,
headless=False,
use_persistent_context=True,
)
async with AsyncWebCrawler(config=browser_config) as crawler:
await crawler.arun(
url=site_url,
cache_mode=CacheMode.BYPASS,
session_id="session_captcha_test"
)
# 使用 CapSolver SDK 获取 reCAPTCHA 令牌
solution = capsolver.solve({
"type": captcha_type,
"websiteURL": site_url,
"websiteKey": site_key,
})
token = solution["gRecaptchaResponse"]
print("reCAPTCHA 令牌:", token)
js_code = """
const textarea = document.getElementById('g-recaptcha-response');
if (textarea) {
textarea.value = '""" + token + """';
document.querySelector('button.form-field[type="submit"]').click();
}
"""
wait_condition = """() => {
const items = document.querySelectorAll('h2');
return items.length > 1;
}"""
run_config = CrawlerRunConfig(
cache_mode=CacheMode.BYPASS,
session_id="session_captcha_test",
js_code=js_code,
js_only=True,
wait_for="js:" + wait_condition
)
result_next = await crawler.arun(
url=site_url,
config=run_config,
)
print(result_next.markdown)
if __name__ == "__main__":
asyncio.run(main())代码分析:
- CapSolver SDK 调用: 调用
capsolver.solve方法,使用ReCaptchaV2TaskProxyLess类型、websiteURL和websiteKey来获取gRecaptchaResponse令牌。这个令牌是 CapSolver 提供的解决方案。 - JavaScript 注入 (
js_code):js_code字符串包含 JavaScript,用于定位页面上的g-recaptcha-response文本区域元素,并将其值设置为获取到的令牌。随后,它模拟点击提交按钮,确保表单使用有效的 CAPTCHA 令牌提交。 wait_for条件: 定义了一个wait_condition来确保 Crawl4AI 等待特定元素出现在页面上,表示提交成功并且页面已加载新内容。
集成方法2:CapSolver 浏览器扩展集成
在直接 API 注入可能复杂或不理想的情况下,CapSolver 的浏览器扩展提供了一个替代方案。这种方法利用扩展在 Crawl4AI 管理的浏览器上下文中自动检测和解决 CAPTCHA 的能力。
工作原理:
- 使用
user_data_dir启动浏览器: 配置 Crawl4AI 以使用指定的user_data_dir启动浏览器实例,以保持持久上下文。 - 安装和配置扩展: 手动将 CapSolver 扩展安装到此浏览器配置文件中,并配置您的 CapSolver API 密钥。您还可以在扩展的
config.js文件中预先配置apiKey和manualSolving参数。 - 导航到 CAPTCHA 页面: Crawl4AI 导航到包含 reCAPTCHA v2 的页面。
- 自动或手动解决: 根据扩展的
manualSolving配置,CAPTCHA 会在页面加载时自动解决,或者您可以通过注入的 JavaScript 手动触发解决。 - 验证: 一旦解决,令牌将由扩展自动处理,后续操作如表单提交将携带有效的验证。
示例代码:reCAPTCHA v2 的扩展集成(自动解决)
此示例展示了如何配置 Crawl4AI 使用带有 CapSolver 扩展的浏览器配置文件进行 reCAPTCHA v2 的自动解决。
python
import asyncio
import time
from crawl4ai import *
# TODO: 设置您的配置
user_data_dir = "/browser-profile/Default1" # 确保此路径正确并包含您配置好的扩展
browser_config = BrowserConfig(
verbose=True,
headless=False,
user_data_dir=user_data_dir,
use_persistent_context=True,
proxy="http://127.0.0.1:13120", # 可选:如果需要配置代理
)
async def main():
async with AsyncWebCrawler(config=browser_config) as crawler:
result_initial = await crawler.arun(
url="https://recaptcha-demo.appspot.com/recaptcha-v2-checkbox.php",
cache_mode=CacheMode.BYPASS,
session_id="session_captcha_test"
)
# 扩展会自动在页面加载时解决 CAPTCHA。
# 您可能需要添加等待条件或 time.sleep 来允许 CAPTCHA 解决后再继续后续操作。
time.sleep(30) # 示例等待,根据需要调整
# CAPTCHA 解决后继续其他 Crawl4AI 操作
# 例如,检查成功提交后出现的元素
# print(result_initial.markdown) # 您可以在等待后检查页面内容
if __name__ == "__main__":
asyncio.run(main())代码分析:
user_data_dir: 此参数对 Crawl4AI 来说至关重要,用于启动保留 CapSolver 扩展及其配置的浏览器实例。确保路径指向一个包含扩展的有效的浏览器配置文件目录。- 自动解决: 在扩展配置中将
manualSolving设置为false(或默认值),扩展将在页面加载时自动检测并解决 reCAPTCHA v2。包含time.sleep作为占位符,以允许扩展有足够的时间解决 CAPTCHA,然后再尝试任何后续操作。
示例代码:reCAPTCHA v2 的扩展集成(手动解决)
如果您希望在爬虫逻辑的特定点手动触发 CAPTCHA 解决,可以将扩展的 manualSolving 参数设置为 true,然后使用 js_code 点击扩展提供的解决按钮。
python
import asyncio
import time
from crawl4ai import *
# TODO: 设置您的配置
user_data_dir = "/browser-profile/Default1" # 确保此路径正确并包含您配置好的扩展
browser_config = BrowserConfig(
verbose=True,
headless=False,
user_data_dir=user_data_dir,
use_persistent_context=True,
proxy="http://127.0.0.1:13120", # 可选:如果需要配置代理
)
async def main():
async with AsyncWebCrawler(config=browser_config) as crawler:
result_initial = await crawler.arun(
url="https://recaptcha-demo.appspot.com/recaptcha-v2-checkbox.php",
cache_mode=CacheMode.BYPASS,
session_id="session_captcha_test"
)
# 等待片刻,让页面加载并让扩展准备就绪
time.sleep(6)
# 使用 js_code 触发 CapSolver 扩展提供的手动解决按钮
js_code = """
let solverButton = document.querySelector('#capsolver-solver-tip-button');
if (solverButton) {
const clickEvent = new MouseEvent('click', {
bubbles: true,
cancelable: true,
view: window
});
solverButton.dispatchEvent(clickEvent);
}
"""
print(js_code)
run_config = CrawlerRunConfig(
cache_mode=CacheMode.BYPASS,
session_id="session_captcha_test",
js_code=js_code,
js_only=True,
)
result_next = await crawler.arun(
url="https://recaptcha-demo.appspot.com/recaptcha-v2-checkbox.php",
config=run_config
)
print("JS 执行结果:", result_next.js_execution_result)
# 在手动触发后允许 CAPTCHA 解决的时间
time.sleep(30) # 示例等待,根据需要调整
# 继续其他 Crawl4AI 操作
if __name__ == "__main__":
asyncio.run(main())代码分析:
manualSolving: 在运行此代码之前,请确保 CapSolver 扩展的config.js中manualSolving设置为true。- 触发解决:
js_code模拟点击扩展提供的#capsolver-solver-tip-button按钮。这使您能够精确控制 CAPTCHA 解决过程的触发时机。
结论
Crawl4AI 与 CapSolver 的集成提供了强大且灵活的解决方案,用于绕过 reCAPTCHA v2,显著提升了网络爬虫操作的效率和可靠性。无论您选择 API 集成的精确控制,还是浏览器扩展集成的简化设置,这两种方法都能确保 reCAPTCHA v2 不再成为您数据收集目标的障碍。
通过自动化 CAPTCHA 解决,开发人员可以专注于提取有价值的数据,确信他们的爬虫可以无缝地访问受保护的网站。Crawl4AI 的先进爬取能力和 CapSolver 的强大 CAPTCHA 解决技术之间的这种协同作用标志着自动化网络数据提取的重要进展。
参考资料
合规声明: 本博客提供的信息仅供参考。CapSolver 致力于遵守所有适用的法律和法规。严禁以非法、欺诈或滥用活动使用 CapSolver 网络,任何此类行为将受到调查。我们的验证码解决方案在确保 100% 合规的同时,帮助解决公共数据爬取过程中的验证码难题。我们鼓励负责任地使用我们的服务。如需更多信息,请访问我们的服务条款和隐私政策。
更多
![如何使用Selenium [Python] 通过Capsolver扩展解决reCaptcha v2](https://assets.capsolver.com/prod/posts/solve-recaptcha-with-selenium-python/9df0c69facb932640c0dd4d2cfa69bbf.jpg)
如何使用 Selenium [Python] 配合 CapSolver 扩展程序解决 reCAPTCHA V2
学习如何使用Selenium Python和Capsolver扩展无缝解决reCAPTCHA v2,一份关于有效设置和自动化验证码解决方案的详细指南

Ethan Collins
05-Nov-2025

CapSolver 扩展 - 在您的浏览器中解决 reCAPTCHA
使用Capsolver验证码求解器扩展轻松解决任何网页上的reCaptcha v2 / v3 / 隐形 / 企业版
Emma Foster
27-Oct-2025

如何在网页抓取中使用Python解决reCAPTCHA问题
学习如何使用Python和Capsolver在网页抓取中解决reCAPTCHA v2和v3。分步指南、代理选项和代码示例,用于无缝自动化。
Ethan Collins
24-Oct-2025

人工智能驱动的SEO自动化:如何解决验证码以实现更智能的SERP数据收集
发现人工智能驱动的SEO自动化如何克服验证码难题,用于更智能的SERP数据收集,并了解reCAPTCHA v2/v3解决方案
Ethan Collins
23-Oct-2025

如何破解reCAPTCHA v2:reCAPTCHA v2 破解指南
学习如何使用CapSolver自动解决Google reCAPTCHA v2。了解API和SDK集成、分步指南以及优惠代码,以简化网络爬虫、自动化和开发项目中的验证码解决过程。
Ethan Collins
22-Oct-2025

reCAPTCHA 求解器 自动识别与求解方法
学习如何使用先进的AI和OCR技术自动识别和解决Google reCAPTCHA v2、v3、不可见版和企业版挑战
Ethan Collins
22-Oct-2025