








Crawl4AIにおけるCloudflare Turnstileの解決方法とCapSolver統合

Sora Fujimoto
AI Solutions Architect
21-Oct-2025

導入
クラウドフレア・ターニスティールは、ユーザーに干渉するチャレンジなしで正当なユーザーを検証するためのスマートなCAPTCHAの代替です。これは、ブラウザの動作や特性を評価してトークンを発行し、そのトークンをサーバーに送信して検証します。人間の訪問者とボットをスムーズに区別することを目指しています。プライバシーを保護し、ユーザーに優しい設計となっていますが、ウェブスクレイピングやデータ抽出ツールにとっては、いくつかの大きな課題をもたらします。
この記事では、高度なウェブクローラーであるCrawl4AIと、CAPTCHAおよびアンチボットソリューションサービスとしてリーディングを誇るCapSolverを統合して、クラウドフレア・ターニスティールの保護を効果的に回避する方法について詳しく説明します。APIベースの統合とブラウザ拡張機能ベースの統合の2つの方法をカバーし、実用的なコード例と説明を提供して、ウェブ自動化タスクがスムーズに進行できるようにします。
クラウドフレア・ターニスティールの理解とウェブスクレイピングにおける課題
クラウドフレア・ターニスティールは、訪問者の行動やブラウザの特性を評価してトークンを発行し、そのトークンをサーバーに送信して検証します。プライバシーを保護し、ユーザーに優しい設計となっていますが、ウェブクローラーにとっては次の課題があります。
- 非表示の検証: 明示的なユーザー操作(チェックボックスのクリックやパズルの解決など)が不要で、ボットが検出および対応するのが難しくなります。
- 動的なJavaScript実行: 検証プロセスはブラウザ内のJavaScript実行に大きく依存しており、クローラーで使用されるヘッドレスブラウザがそれを正しく処理しなければなりません。
- トークンの挿入: トークンが有効であることを確認するために、特定の入力フィールド(通常は
cf-turnstile-response)にトークンを挿入する必要があります。
CapSolverは、高度なAIアルゴリズムを活用して、クラウドフレア・ターニスティールのCAPTCHAを高精度で迅速に解決するソリューションを提供します。Crawl4AIと統合することで、この複雑なアンチボットメカニズムを管理可能なステップに変換し、ウェブ自動化タスクがスムーズかつ中断することなく進行できるようにします。
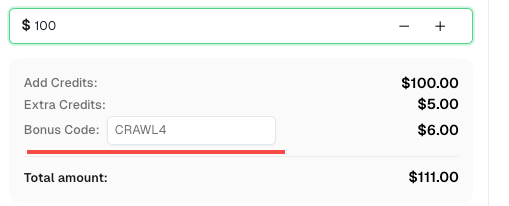
💡 Crawl4AI統合ユーザー向けの特典:
本統合を記念して、このチュートリアルを通じて登録したCapSolverユーザーに、6%のボーナスコード —CRAWL4を提供しています。
ダッシュボードでチャージ時にコードを入力すると、即座に6%のクレジットが追加されます。
統合方法1: Crawl4AIとのCapSolver API統合
API統合方法は正確な制御を提供し、柔軟性があるため多くの場合で好まれます。これは、CapSolverを用いてターニスティールトークンを取得し、その後Crawl4AIのjs_code機能を介してターゲットウェブページの適切な入力要素にこのトークンを挿入することを含みます。
仕組み:
- 初期アクセス: Crawl4AIがターゲットウェブページにアクセスし、クラウドフレア・ターニスティールを含みます。
- ターニスティールトークンの取得: Pythonスクリプトで、
AntiTurnstileTaskProxyLessタイプとwebsiteURL、websiteKeyを指定してCapSolverのAPIを呼び出します。CapSolverは必要なターニスティールトークンを返します。 - トークンの挿入と送信:
js_codeパラメータを使用して、Crawl4AIのCrawlerRunConfig内で取得したトークンをcf-turnstile-responseという名前のinput要素に挿入します。トークンの挿入後、送信ボタンをクリックするか、トークンに依存する次のアクションをトリガーします。 - 操作の継続: 有効なターニスティールトークンが正しく配置されると、Crawl4AIは後続の操作を継続できます。これにより、クラウドフレア・ターニスティールを効果的に回避できます。
例: クラウドフレア・ターニスティールのAPI統合
次のPythonコードは、CapSolverのAPIをCrawl4AIと統合してクラウドフレア・ターニスティールを解決する方法を示しています。この例は、クラウドフレア・ターニスティールのデモページをターゲットにしています。
python
import asyncio
import capsolver
from crawl4ai import *
# TODO: あなたの設定を設定してください
api_key = "CAP-xxxxxxxxxxxxxxxxxxxxx" # CapSolverのAPIキー
site_key = "0x4AAAAAAAGlwMzq_9z6S9Mh" # ターゲットサイトのサイトキー
site_url = "https://clifford.io/demo/cloudflare-turnstile" # ターゲットサイトのページURL
captcha_type = "AntiTurnstileTaskProxyLess" # ターゲットのCAPTCHAのタイプ
capsolver.api_key = api_key
async def main():
browser_config = BrowserConfig(
verbose=True,
headless=False,
use_persistent_context=True,
)
async with AsyncWebCrawler(config=browser_config) as crawler:
await crawler.arun(
url=site_url,
cache_mode=CacheMode.BYPASS,
session_id="session_captcha_test"
)
# CapSolver SDKを用いてターニスティールトークンを取得
solution = capsolver.solve({
"type": captcha_type,
"websiteURL": site_url,
"websiteKey": site_key,
})
token = solution["token"]
print("ターニスティールトークン:", token)
js_code = """
document.querySelector(\'input[name="cf-turnstile-response"]\').value = \'"""+token+"""\';
document.querySelector(\'button[type="submit"]\').click();
"""
wait_condition = """() => {
const items = document.querySelectorAll(\'h1\');
return items.length === 0;
}"""
run_config = CrawlerRunConfig(
cache_mode=CacheMode.BYPASS,
session_id="session_captcha_test",
js_code=js_code,
js_only=True,
wait_for=f"js:{wait_condition}"
)
result_next = await crawler.arun(
url=site_url,
config=run_config,
)
print(result_next.markdown)
if __name__ == "__main__":
asyncio.run(main())コード分析:
- CapSolver SDK呼び出し:
capsolver.solveメソッドは、AntiTurnstileTaskProxyLessタイプ、websiteURL、websiteKeyを指定して呼び出され、ターニスティールトークンが取得されます。このトークンはCapSolverが提供する解決策です。 - JavaScript挿入(
js_code):js_code文字列には、ページ上のinput要素name="cf-turnstile-response"を検索し、取得したトークンをvalueプロパティに割り当て、その後送信ボタンをクリックするJavaScriptが含まれています。これにより、フォームが有効なターニスティールトークンで送信されます。 wait_for条件:wait_conditionは、ページ上の特定の変化(例:h1要素の消失)が発生するまでCrawl4AIが待機することを定義しています。これにより、送信およびナビゲーションが成功したことを示します。
統合方法2: CapSolverブラウザ拡張機能との統合
CapSolverのブラウザ拡張機能は、Crawl4AIが管理する永続的なブラウザコンテキスト内で自動解決機能を活用する場合に、クラウドフレア・ターニスティールを扱う簡略化された方法を提供します。
仕組み:
- 永続的なブラウザコンテキスト: Crawl4AIを設定して
user_data_dirを使用し、インストールされたCapSolver拡張機能とその設定を保持するブラウザインスタンスを起動します。 - 拡張機能のインストールと設定: このブラウザプロファイルにCapSolver拡張機能を手動でインストールし、CapSolverのAPIキーを設定します。拡張機能はターニスティールチャレンジを自動的に解決するように設定できます。
- ターゲットページにアクセス: Crawl4AIがクラウドフレア・ターニスティールで保護されたウェブページにアクセスします。
- 自動解決: ブラウザコンテキスト内で実行されるCapSolver拡張機能は、ターニスティールチャレンジを検出し、自動的に解決します。その後、トークンが
cf-turnstile-response入力フィールドに挿入されます。 - アクションの継続: ターニスティールが拡張機能によって解決されると、Crawl4AIはスクレイピングタスクを継続できます。ブラウザコンテキストには、後続のリクエストに必要な有効なトークンがすでに含まれています。
例: クラウドフレア・ターニスティールの拡張機能統合(自動解決)
この例は、Crawl4AIがCapSolver拡張機能を備えたブラウザプロファイルを設定して、クラウドフレア・ターニスティールを自動的に解決する方法を示しています。
python
import asyncio
import time
from crawl4ai import *
# TODO: あなたの設定を設定してください
user_data_dir = "/browser-profile/Default1" # このパスが正しく設定されており、拡張機能が構成されていることを確認してください
browser_config = BrowserConfig(
verbose=True,
headless=False,
user_data_dir=user_data_dir,
use_persistent_context=True,
proxy="http://127.0.0.1:13120", # 必要に応じてプロキシを構成してください
)
async def main():
async with AsyncWebCrawler(config=browser_config) as crawler:
result_initial = await crawler.arun(
url="https://clifford.io/demo/cloudflare-turnstile", # クラウドフレア・ターニスティールのデモURLを使用してください
cache_mode=CacheMode.BYPASS,
session_id="session_captcha_test"
)
# 拡張機能はページ読み込み時にCAPTCHAを自動的に解決します。
# CAPTCHAが解決されるまでに待機条件またはtime.sleepが必要な場合があります。
# ここでは拡張機能が動作するための一般的な待機時間を示しています。
time.sleep(30) # 例としての待機時間、拡張機能の動作に応じて調整してください
# CAPTCHAが解決された後、他のCrawl4AI操作を継続します
# たとえば、成功した検証後に表示される要素やコンテンツをチェックできます
# print(result_initial.markdown) # 待機後のページコンテンツを確認できます
if __name__ == "__main__":
asyncio.run(main())コード分析:
user_data_dir: このパラメータは、インストールされたCapSolver拡張機能とその設定を保持するブラウザインスタンスを起動するためにCrawl4AIにとって不可欠です。拡張機能がインストールされている有効なブラウザプロファイルディレクトリへのパスを確認してください。- 自動解決: CapSolver拡張機能は、ターニスティールチャレンジを自動的に検出し、解決するように設計されています。拡張機能が背景で動作する時間を確保するため、一般的な例として
time.sleepが含まれています。より堅牢な解決策には、Crawl4AIのwait_for機能を使用して、ターニスティールの解決が成功したことを示す特定のページ変更をチェックすることを検討してください。
結論
Crawl4AIとCapSolverの統合は、クラウドフレア・ターニスティールを回避するための強力で効率的なソリューションを提供し、ウェブスクレイピング操作の信頼性を大幅に向上させます。API統合の正確な制御またはブラウザ拡張機能によるシームレスな自動化を好むかどうかに関わらず、両方の方法はクラウドフレア・ターニスティールがデータ収集目標を妨げることなく、スムーズに動作することを保証します。
ターニスティールの解決を自動化することで、開発者は価値あるデータの抽出に集中でき、クローラーが保護されたウェブサイトをシームレスにナビゲートできると確信できます。Crawl4AIの高度なクローリング機能とCapSolverの強力なアンチボット技術のシナジーは、自動化されたウェブデータ抽出において重要な一歩を踏み出しています。
一般的な質問(FAQ)
Q1: クラウドフレア・ターニスティールとは何か、従来のCAPTCHAとどう違うのか?
A1: クラウドフレア・ターニスティールは、ユーザーに干渉するチャレンジなしで正当なユーザーを検証するCAPTCHAの代替です。従来のCAPTCHAがパズルの解決を必要とするのに対し、ターニスティールは非干渉的なJavaScriptチャレンジをバックグラウンドで実行し、ユーザー体験をスムーズにしながら人間とボットを効果的に区別することを目指しています。
Q2: クラウドフレア・ターニスティールで保護されたウェブサイトをスクレイピングするのはなぜ難しいのか?
A2: ターニスティールの非表示性、動的なJavaScript実行への依存、および特定の入力フィールド(cf-turnstile-response)に有効なトークンを挿入する必要性により、自動ウェブスクレイパーにとって困難です。ブラウザの特性やユーザーの行動を評価し、本物のユーザー操作を模倣しないリクエストをブロックすることがあります。
Q3: CapSolverはクラウドフレア・ターニスティールを回避するのをどうやって助けるのか?
A3: CapSolverは、AntiTurnstileTaskProxyLessなどの専門的なサービスを提供してクラウドフレア・ターニスティールチャレンジを解決します。必要なターニスティールトークンを取得し、その後Crawl4AIがターゲットウェブページに挿入することで保護を回避します。
Q4: Crawl4AIとCapSolverでクラウドフレア・ターニスティールを統合する主な2つの方法は何か?
A4: 主な2つの方法は、API統合とブラウザ拡張機能統合です。API統合では、CapSolverのAPIを呼び出してトークンを取得し、Crawl4AIのjs_codeを介して挿入します。ブラウザ拡張機能統合では、CapSolver拡張機能が永続的なブラウザコンテキスト内でターニスティールチャレンジを自動的に処理します。
Q5: クラウドフレア・ターニスティールにCrawl4AIとCapSolverを統合する利点は何か?
A5: この統合により、ターニスティールの自動処理、クローリング効率の向上、アンチボットメカニズムに対するクローラーの耐性の向上、手動介入を最小限に抑えて運用コストを削減し、ウェブデータ抽出を中断することなく行うことが可能になります。
参考資料
コンプライアンス免責事項: このブログで提供される情報は、情報提供のみを目的としています。CapSolverは、すべての適用される法律および規制の遵守に努めています。CapSolverネットワークの不法、詐欺、または悪用の目的での使用は厳格に禁止され、調査されます。私たちのキャプチャ解決ソリューションは、公共データのクローリング中にキャプチャの問題を解決する際に100%のコンプライアンスを確保しながら、ユーザーエクスペリエンスを向上させます。私たちは、サービスの責任ある使用を奨励します。詳細については、サービス利用規約およびプライバシーポリシーをご覧ください。
もっと見る

2025年におけるCloudflareの解決方法:CapSolverを使用してCloudflare Turnstileとチャレンジを突破する方法
CloudflareのチャレンジとTurnstile CAPTCHAを探索し、CapSolver、自動化ブラウザ、高品質なプロキシを使用してそれらを回避する方法を学びます。自動化タスクでのスムーズなCAPTCHA解決のための実用的なPythonおよびNode.jsの例が含まれています。
Sora Fujimoto
03-Nov-2025

2026年におけるCloudflareを回避する方法: 6つの継続的な自動化のための最良の方法
2026年のウェブスクレイピングおよびオートメーションにおいてCloudflare Challenge 5sを解決するための6つの最適な方法を発見してください。詳細な戦略、コード例、およびAIを駆動するキャップソルバーのソリューションの詳細な分析を含みます。
Sora Fujimoto
29-Oct-2025

Cloudflare 5秒チャレンジの解決方法: ウェブスクレイピング向け技術的ガイド
Cloudflareの5秒チャレンジを解決する方法を学びましょう。開発者向けのステップバイステップのガイドで、CapSolverを使用してCloudflareのJavaScriptおよびマネージドチャレンジを乗り越える方法を紹介します。安定したウェブスクレイピングの自動化に役立ちます。
Sora Fujimoto
28-Oct-2025

Crawl4AIにおけるCloudflare Turnstileの解決方法とCapSolver統合
Crawl4AIとCapSolverを統合して、APIおよびブラウザ拡張機能の方法を使用してCloudflare Turnstileの保護を回避する包括的なガイド。スムーズなウェブスクリーピングのために。
Sora Fujimoto
21-Oct-2025

Crawl4AIでのCloudflareチャレンジの解決方法とCapSolver統合
CapSolver APIの統合を活用して、Crawl4AIでCloudflare Challengeを解決する方法を学びましょう。このガイドは、効果的なウェブスクラビングとデータ抽出のためのコード例を提供します。
Sora Fujimoto
21-Oct-2025

2026年のクラウドフレアターニースタイルとチャレンジ5秒の解決方法 | 最高のクラウドフレアソルバー
ウェブスクラピングのトップユースケースと、CapSolverがデータ抽出をスムーズかつ途切れることなく保つ方法を学びましょう。
Sora Fujimoto
17-Oct-2025