








如何在 Crawl4AI 中通过 CapSolver 集成解决 Cloudflare 验证

Emma Foster
Machine Learning Engineer
21-Oct-2025
简介
Cloudflare 挑战是一种复杂的反机器人机制,通常涉及多种检查,包括浏览器指纹识别和用户代理验证,以区分合法用户和自动化流量。这些挑战会显著阻碍网络爬虫和数据提取工作,使得爬虫难以访问目标网站。克服 Cloudflare 挑战需要一个强大且适应性强的解决方案,以模拟真实浏览器行为。
本文提供了一个全面指南,介绍如何将 Crawl4AI(一种先进的网络爬虫)与 CapSolver(领先的验证码和反机器人解决方案服务)集成,以有效绕过 Cloudflare 挑战保护。我们将重点介绍基于 API 的集成方法,提供详细的代码示例和解释,以确保您的网络自动化任务可以顺利进行。
理解 Cloudflare 挑战及其对网络爬虫的复杂性
Cloudflare 挑战比典型的验证码更为激进,通常结合多种技术来识别和阻止机器人:
- 浏览器指纹识别: 分析浏览器的独特特征以检测自动化行为。
- 用户代理验证: 要求特定且一致的用户代理字符串,以匹配真实浏览器版本。
- JavaScript 执行: 在后台执行复杂的 JavaScript 以验证浏览器功能和类似人类的交互。
- Cookie 管理: 设置并验证特定的 Cookie 作为挑战解决过程的一部分。
CapSolver 提供了 AntiCloudflareTask 类型,专门用于解决这些复杂挑战,通过提供必要的令牌、Cookie 甚至推荐特定的用户代理。当与 Crawl4AI 集成时,这使您的爬虫能够成功通过 Cloudflare 保护的网站。
集成方法:使用 CapSolver API 与 Crawl4AI 集成
API 集成方法对于处理 Cloudflare 挑战至关重要,因为它允许对浏览器配置进行精确控制,并注入必要的令牌和 Cookie。此方法涉及使用 CapSolver 获取所需的挑战解决方案(令牌、Cookie 和用户代理),然后配置 Crawl4AI 使用这些参数。
工作原理:
- 获取 Cloudflare 挑战解决方案: 在启动爬虫之前,使用 CapSolver 的 API 和 SDK 调用,指定
AntiCloudflareTask类型。您需要提供websiteURL、一个proxy(如果适用)以及与 CapSolver 用于解决的浏览器版本匹配的userAgent。 - 配置 Crawl4AI 浏览器: 使用 CapSolver 返回的解决方案(包含
token、cookies和推荐的userAgent)来配置 Crawl4AI 的BrowserConfig。这确保了 Crawl4AI 的浏览器实例能够模拟解决挑战时使用的环境。 - 启动爬虫: 然后 Crawl4AI 使用专门配置的浏览器运行,包括必要的 Cookie 和用户代理,从而绕过 Cloudflare 挑战。
- 继续操作: 成功绕过 Cloudflare 挑战后,Crawl4AI 可以继续在目标网站上执行其数据提取任务。
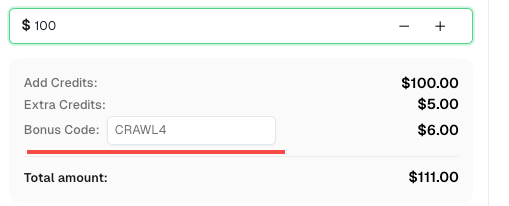
💡 Crawl4AI 集成用户的独家优惠:
为了庆祝此次集成,我们为所有通过本教程注册的 CapSolver 用户提供独家 6% 优惠码 —CRAWL4。
只需在 仪表板 充值时输入该代码,即可立即获得 额外 6% 的积分。
示例代码:Cloudflare 挑战的 API 集成
以下 Python 代码展示了如何将 CapSolver 的 API 与 Crawl4AI 集成以解决 Cloudflare 挑战。此示例针对由 Cloudflare 保护的新闻文章页面。
python
import asyncio
import time
import capsolver
from crawl4ai import *
# TODO:设置您的配置
api_key = "CAP-XXX" # 您的 CapSolver API 密钥
site_url = "https://www.tempo.co/hukum/polisi-diduga-salah-tangkap-pelajar-di-magelang-yang-dituduh-perusuh-demo-2070572" # 您的目标网站页面 URL
captcha_type = "AntiCloudflareTask" # 您的目标验证码类型
api_proxy = "http://127.0.0.1:13120"
capsolver.api_key = api_key
user_data_dir = "./crawl4ai_/browser-profile/Default1493"
# 或
cdp_url = "ws://localhost:xxxx"
async def main():
print("开始解决令牌")
start_time = time.time()
# 使用 CapSolver SDK 获取 Cloudflare 令牌
solution = capsolver.solve({
"type": captcha_type,
"websiteURL": site_url,
"proxy": api_proxy,
"userAgent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36"
})
token_time = time.time()
print(f"解决令牌耗时:{token_time - start_time:.2f} 秒")
# 设置 Cookie
cookies = solution.get("cookies", [])
if isinstance(cookies, dict):
cookies_array = []
for name, value in cookies.items():
cookies_array.append({
"name": name,
"value": value,
"url": site_url,
})
cookies = cookies_array
elif not isinstance(cookies, list):
cookies = []
token = solution["token"]
print("挑战令牌:", token)
browser_config = BrowserConfig(
verbose=True,
headless=False,
use_persistent_context=True,
user_data_dir=user_data_dir,
# cdp_url=cdp_url,
user_agent=solution["userAgent"],
cookies=cookies,
)
async with AsyncWebCrawler(config=browser_config) as crawler:
result = await crawler.arun(
url=site_url,
cache_mode=CacheMode.BYPASS,
session_id="session_captcha_test"
)
print(result.markdown[:500])
if __name__ == "__main__":
asyncio.run(main())代码分析:
- CapSolver SDK 调用:
capsolver.solve方法是核心,使用AntiCloudflareTask类型。它需要websiteURL、proxy和特定的userAgent。CapSolver 处理挑战并返回一个包含token、cookies和用于解决挑战的userAgent的solution对象。 - 浏览器配置: 使用 CapSolver 的解决方案中的信息,精心设置 Crawl4AI 的
BrowserConfig。这包括user_agent和cookies,以确保 Crawl4AI 的浏览器实例完全符合 Cloudflare 挑战解决时的条件。还指定了user_data_dir以保持一致的浏览器配置文件。 - 爬虫执行: 然后 Crawl4AI 使用此精心配置的
browser_config执行其arun方法,使其能够成功访问目标 URL 而不会再次触发 Cloudflare 挑战。
结论
在网页爬取中绕过 Cloudflare 挑战是一项复杂的任务,需要一种高级的方法。Crawl4AI 与 CapSolver 的集成提供了一种强大且有效的解决方案,使开发人员能够无缝地通过这些先进的反机器人保护。通过利用 CapSolver 的专用 AntiCloudflareTask 获取必要的令牌、Cookie 和用户代理,然后配置 Crawl4AI 的浏览器以匹配这些参数,您可以确保网页爬取操作的稳定性和成功率。
Crawl4AI 的先进爬取能力与 CapSolver 的强大反机器人技术之间的这种协同作用,标志着自动化网页数据提取的一个重要进展,使您能够专注于收集有价值的数据,而不受 Cloudflare 保护措施的阻碍。
常见问题(FAQ)
Q1:什么是 Cloudflare 挑战?为什么使用它?
A1: Cloudflare 挑战是一种高级的反机器人机制,旨在验证访问者是否为真实用户或自动化脚本。它采用多种技术,如浏览器指纹识别、用户代理验证和 JavaScript 执行,以保护网站免受恶意机器人、DDoS 攻击和其他威胁。
Q2:为什么 Cloudflare 挑战对网页爬虫特别困难?
A2: Cloudflare 挑战对爬虫来说困难,因为它超越了简单的验证码。它会主动分析浏览器特征,要求一致的用户代理字符串,执行复杂的 JavaScript,并管理特定的 Cookie。这种复杂的检测使得自动化工具很难在没有专用解决方案的情况下模拟真实的人类交互。
Q3:CapSolver 如何帮助绕过 Cloudflare 挑战?
A3: CapSolver 提供了一种专用任务类型 AntiCloudflareTask,用于解决 Cloudflare 挑战。它处理挑战并返回一个包含令牌、必要 Cookie 和推荐用户代理的解决方案。这些信息随后用于配置 Crawl4AI,使其成功绕过挑战。
Q4:在使用 Cloudflare 挑战集成 Crawl4AI 和 CapSolver 时有哪些关键注意事项?
A5: 关键注意事项包括确保在 Crawl4AI 配置中使用的 userAgent 与 CapSolver 提供的一致,正确处理并注入 CapSolver 返回的 cookies,以及在爬取操作需要时提供 proxy。这些步骤确保 Crawl4AI 的浏览器环境准确反映挑战解决时的条件。
参考资料
合规声明: 本博客提供的信息仅供参考。CapSolver 致力于遵守所有适用的法律和法规。严禁以非法、欺诈或滥用活动使用 CapSolver 网络,任何此类行为将受到调查。我们的验证码解决方案在确保 100% 合规的同时,帮助解决公共数据爬取过程中的验证码难题。我们鼓励负责任地使用我们的服务。如需更多信息,请访问我们的服务条款和隐私政策。
更多

如何在2025年解决Cloudflare:通过CapSolver解决Cloudflare Turnstile和挑战
探索 Cloudflare 的挑战和 Turnstile 验证码,并学习如何使用 CapSolver、自动化浏览器和高质量代理来绕过它们。包含用于自动化任务中无缝验证码解决的实用 Python 和 Node.js 示例。
Emma Foster
03-Nov-2025

如何在2026年解决Cloudflare:6种最佳方法实现不间断自动化
发现解决Cloudflare 5秒挑战的6种最佳方法,适用于2026年的网络爬虫和自动化。包含详细策略、代码示例以及对人工智能驱动的CapSolver解决方案的深入分析。

Ethan Collins
30-Oct-2025

如何解决Cloudflare 5秒挑战:网页爬虫技术指南
学习如何使用高级CAPTCHA求解API解决Cloudflare 5秒挑战。针对开发者的分步指南,使用CapSolver克服Cloudflare JavaScript和Managed Challenges,实现稳定网络爬虫自动化。
Emma Foster
28-Oct-2025

如何在 Crawl4AI 中通过 CapSolver 集成解决 Cloudflare 验证
学习如何使用 CapSolver API 集成在 Crawl4AI 中解决 Cloudflare 验证。本指南提供用于有效网络爬虫和数据提取的代码示例。
Emma Foster
21-Oct-2025

如何在Crawl4AI中通过CapSolver集成解决Cloudflare Turnstile人机验证
一份全面指南,介绍如何通过API和浏览器扩展方法将Crawl4AI与CapSolver集成,以绕过Cloudflare Turnstile的保护措施,实现无缝网络爬虫。
Emma Foster
21-Oct-2025

如何解决Cloudflare Turnstile和5秒挑战 | 2026年最佳Cloudflare破解工具
网络爬虫的顶级应用场景及了解CapSolver如何确保数据提取的流畅与不间断

Anh Tuan
17-Oct-2025