








如何在Crawl4AI中通过CapSolver集成解决验证码

Ethan Collins
Pattern Recognition Specialist
26-Sep-2025

1. 简介
网页自动化和数据提取对于许多应用至关重要,但验证码(CAPTCHA)常常会中断这些流程,导致延迟和失败。
为了解决这个问题,Crawl4AI 和 CapSolver 进行了合作。Crawl4AI 提供了先进的、自适应的网页爬取和浏览器控制功能,而 CapSolver 提供了高精度和快速的验证码解决服务。这种协作使开发者能够实现无缝、不间断的网页自动化和数据收集。
1.1. 集成目标
Crawl4AI 与 CapSolver 集成的核心目标是:
- 将 Crawl4AI 的高效爬取能力与 CapSolver 的验证码解决能力相结合:通过深度集成,Crawl4AI 在遇到验证码时可以无缝调用 CapSolver 的服务,实现自动绕过。
- 实现自动化、无障碍的网页数据抓取:消除由验证码造成的障碍,确保数据抓取任务的连续性和完整性,显著减少人工干预。
- 提升爬虫的稳定性和成功率:在面对复杂的反机器人机制时,提供稳定可靠的解决方案,从而显著提高数据抓取的成功率和效率。
2. Crawl4AI 概述
Crawl4AI 是一个开源的、适合大语言模型(LLM)的网页爬虫和数据提取工具,旨在满足现代 AI 应用的需求。它可以将复杂的网页内容转换为干净的、结构化的 Markdown 格式,大大简化后续的数据处理和分析。
2.1. 核心功能
- 适合大语言模型:Crawl4AI 可以生成高质量的 Markdown 内容并支持结构化提取,是构建 RAG(检索增强生成)、AI 代理和数据管道的理想选择。它会自动过滤掉噪声,只保留对 LLM 有价值的信息。
- 高级浏览器控制:提供强大的无头浏览器控制功能,支持会话管理和代理集成。这意味着 Crawl4AI 可以模拟真实用户行为,有效绕过反机器人检测,并处理动态加载的内容。
- 高性能和自适应爬取:Crawl4AI 采用智能自适应爬取算法,可以根据内容相关性智能判断何时停止爬取,避免盲目抓取大量无关页面,从而提高效率并降低成本。在处理大规模网站时,其速度和效率表现突出。
- 隐身模式:通过模拟真实用户行为有效避免机器人检测。
- 身份感知爬取:可以保存和重用 cookies 和 localStorage,支持登录后的网站爬取,确保爬虫被识别为合法用户。
2.2. 使用场景
Crawl4AI 适用于市场调研、新闻聚合或电子商务产品收集等大规模数据抓取。它能够处理动态的、JavaScript 密集的网站,并作为 AI 代理和自动化数据管道的可靠数据源。
Crawl4AI 展望未来,希望数字数据成为真正的资本资产。他们的白皮书描述了一个共享数据经济,使个人和企业能够构建、评估并选择性地货币化他们的真实数据——这与 CapSolver 通过无缝验证码解决和自动化数据访问来解锁人类生成数据价值的使命高度契合。
3. CapSolver 概述
CapSolver 是一个领先的自动化验证码解决服务,利用先进的 AI 技术为各种复杂的验证码挑战提供快速且准确的解决方案。它的目标是帮助开发者和企业克服验证码障碍,确保自动化流程的顺利运行。
- 支持多种验证码类型:CapSolver 可以解决市场上主流的验证码类型,包括但不限于 reCAPTCHA v2/v3、Cloudflare Turnstile、ImageToText(OCR)、AWS WAF 等。其广泛的兼容性使其成为通用的验证码解决方案。
- 高识别率和快速响应:借助强大的 AI 算法和大规模计算资源,CapSolver 实现了极高的验证码识别准确率,并在毫秒级时间内返回解决方案,最大程度减少爬取延迟。
- 易于 API 集成:CapSolver 提供清晰简洁的 API 接口和详细的 SDK 文档,使开发者能够轻松地将其服务快速集成到现有的爬虫框架和自动化工具中,无论是在 Python、Node.js 还是其他语言环境中。
4. 使用 Crawl4AI 和 CapSolver 解决验证码挑战
4.1. 痛点
在集成 CapSolver 之前,即使拥有强大的爬取能力,Crawl4AI 在遇到验证码时仍常常面临以下痛点:
- 数据采集过程被中断:一旦爬虫触发验证码,整个数据抓取任务就会被阻塞,需要人工干预来解决,严重降低自动化效率。
- 稳定性下降:验证码的出现导致爬虫任务不稳定,成功率波动,难以确保数据流的连续性。
- 开发成本增加:开发者需要投入额外的时间和精力去寻找、测试和维护各种验证码绕过方案,或者手动解决验证码,增加了开发和运营成本。
- 数据时效性受损:由验证码引起的延迟可能导致数据失去时效性,影响基于实时数据的决策。
4.2. 解决方案:如何通过 Crawl4AI 与 CapSolver 集成解决
Crawl4AI 与 CapSolver 的集成提供了一个优雅而强大的解决方案,彻底解决了上述痛点。整体思路是:当 Crawl4AI 在爬取过程中检测到验证码时,会自动触发 CapSolver 服务进行识别和解决,并无缝地将解决方案注入爬取流程,从而实现自动绕过验证码。
集成价值:
- 自动化验证码处理:开发者可以直接在 Crawl4AI 中调用 CapSolver API,无需人工干预,实现验证码的自动识别和解决。
- 提升爬取效率:通过自动绕过验证码,显著减少爬取中断,加快数据采集过程。
- 增强爬虫鲁棒性:面对多样化的反机器人机制,集成解决方案提供了更强的适应性和稳定性,确保爬虫在各种复杂环境中高效运行。
- 降低运营成本:减少人工干预需求,优化资源分配,降低数据抓取的长期运营成本。
Crawl4AI 与 CapSolver 的集成主要涉及两种方法:API 集成和浏览器扩展集成。推荐使用 API 集成,因为它更灵活和精确,避免了浏览器扩展在复杂页面上可能遇到的注入时机和准确性问题。
5. 如何使用 CapSolver 的 API 进行集成
API 集成需要结合 Crawl4AI 的 js_code 功能。基本步骤如下:
- 导航到包含验证码的页面:Crawl4AI 正常访问目标网页。
- 使用 CapSolver SDK 获取 Token:在 Crawl4AI 的 Python 代码中,通过 CapSolver SDK 调用 CapSolver API,发送验证码相关参数(例如
siteKey、websiteURL)到 CapSolver 服务以获取验证码解决方案(通常为 Token)。 - 使用 Crawl4AI 的
CrawlerRunConfig注入 Token:使用CrawlerRunConfig方法的js_code参数,将 CapSolver 返回的 Token 注入到目标页面的相应元素中。例如,对于 reCAPTCHA v2,Token 通常需要注入到g-recaptcha-response元素中。 - 继续其他 Crawl4AI 操作:在成功注入 Token 后,Crawl4AI 可以继续执行后续操作,如点击和表单提交,从而成功绕过验证码。
5.1. 解决 reCAPTCHA v2
reCAPTCHA v2 是一种常见的“我不是机器人”复选框验证码。要解决它,需要通过 CapSolver 获取 gRecaptchaResponse Token 并注入到页面中。如果您不确定如何设置参数,请查看 教程博客 以自动检测验证码并提取配置。
示例代码分析:
用户提供的代码展示了如何使用 capsolver.solve 方法获取 reCAPTCHA v2 Token,并通过 js_code 将其分配给 g-recaptcha-response 文本区域,然后模拟点击提交按钮。这种方法确保在提交表单时正确携带验证码 Token。
python
import asyncio
import capsolver
from crawl4ai import *
# TODO: 设置您的配置
api_key = "CAP-xxxxxxxxxxxxxxxxxxxxx" # 您的 CapSolver API 密钥
site_key = "6LfW6wATAAAAAHLqO2pb8bDBahxlMxNdo9g947u9" # 您目标网站的站点密钥
site_url = "https://recaptcha-demo.appspot.com/recaptcha-v2-checkbox.php" # 您目标网站的页面 URL
captcha_type = "ReCaptchaV2TaskProxyLess" # 您目标验证码的类型
capsolver.api_key = api_key
async def main():
browser_config = BrowserConfig(
verbose=True,
headless=False,
use_persistent_context=True,
)
async with AsyncWebCrawler(config=browser_config) as crawler:
await crawler.arun(
url=site_url,
cache_mode=CacheMode.BYPASS,
session_id="session_captcha_test"
)
# 使用 CapSolver SDK 获取验证码 Token
solution = capsolver.solve({
"type": captcha_type,
"websiteURL": site_url,
"websiteKey": site_key,
})
token = solution["gRecaptchaResponse"]
print("验证码 Token:", token)
js_code = """
const textarea = document.getElementById(\'g-recaptcha-response\');
if (textarea) {
textarea.value = \"""" + token + """\";
document.querySelector(\'button.form-field[type="submit"]\').click();
}
"""
wait_condition = """() => {
const items = document.querySelectorAll(\'h2\');
return items.length > 1;
}"""
run_config = CrawlerRunConfig(
cache_mode=CacheMode.BYPASS,
session_id="session_captcha_test",
js_code=js_code,
js_only=True,
wait_for=f"js:{wait_condition}"
)
result_next = await crawler.arun(
url=site_url,
config=run_config,
)
print(result_next.markdown)
if __name__ == "__main__":
asyncio.run(main())如果 v2 Token 无效,请通过浏览器扩展获取 JSON 配置并发送给我们的支持团队以提高 Token 分数:解决 reCAPTCHA v2、不可见 v2、v3、v3 企业版 ≥0.9 分。
5.2. 解决 reCAPTCHA v3
reCAPTCHA v3 是一种隐形验证码,通常在后台运行并返回一个评分。在解决 reCAPTCHA v3 之前,请阅读 CapSolver 的 reCAPTCHA v3 文档 以了解所需参数以及如何获取它们。我们将使用 reCAPTCHA v3 演示 作为示例。

-
与 v2 不同,reCAPTCHA v3 是隐形的,因此 Token 注入可能比较棘手。过早注入 Token 可能会被原始 Token 覆盖,而过晚注入可能错过验证步骤。在该演示网站上,访问页面会自动触发 Token 生成和验证。
-
通过观察页面,我们看到解决 reCAPTCHA 会触发一个 fetch 请求来验证 Token。解决方案是提前从 CapSolver 获取 Token,并拦截 fetch 请求,在合适的时机替换原始 Token。
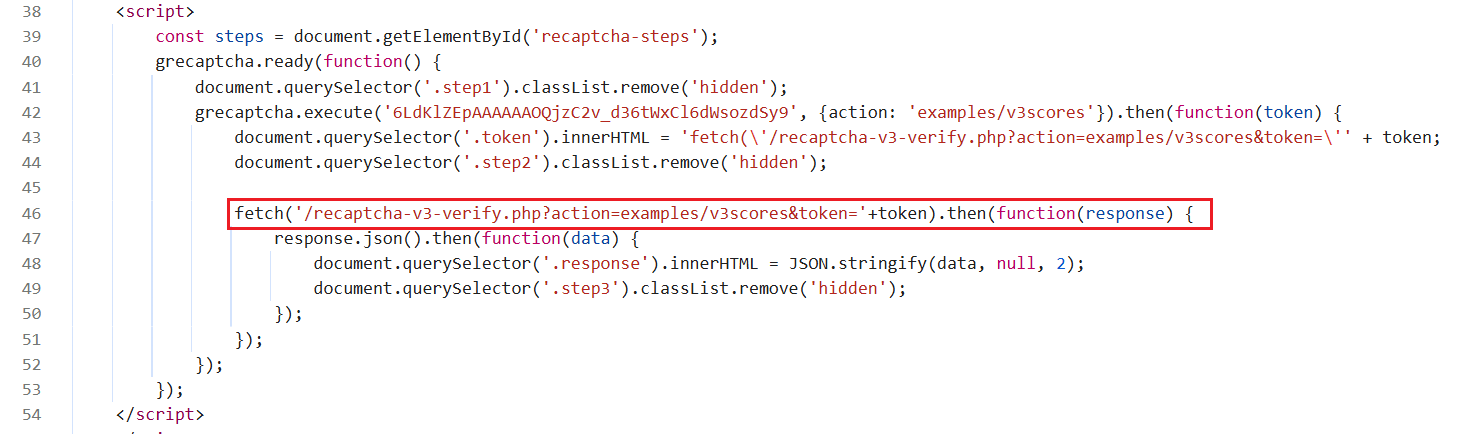
示例代码分析:
代码拦截了 window.fetch 方法,当发送请求到 /recaptcha-v3-verify.php 时,会用从 CapSolver 提前获取的 Token 替换原始请求的 Token。这种高级拦截技术确保即使是对直接操作困难的动态生成的 v3 验证码也能被有效绕过。
python
import asyncio
import capsolver
from crawl4ai import *
# TODO: 设置您的配置
api_key = "CAP-xxxxxxxxxxxxxxxxxxxxx" # 您的 CapSolver API 密钥
site_key = "6LdKlZEpAAAAAAOQjzC2v_d36tWxCl6dWsozdSy9" # 您目标网站的站点密钥
site_url = "https://recaptcha-demo.appspot.com/recaptcha-v3-request-scores.php" # 您目标网站的页面 URL
page_action = "examples/v3scores" # 您目标网站的页面操作
captcha_type = "ReCaptchaV3TaskProxyLess" # 您目标验证码的类型
capsolver.api_key = api_key
async def main():
browser_config = BrowserConfig(
verbose=True,
headless=False,
use_persistent_context=True,
)
# 通过 CapSolver SDK 获取 reCAPTCHA Token
solution = capsolver.solve({
"type": captcha_type,
"websiteURL": site_url,
"websiteKey": site_key,
"pageAction": page_action,
})
token = solution["gRecaptchaResponse"]
print("reCAPTCHA Token:", token)
async with AsyncWebCrawler(config=browser_config) as crawler:
await crawler.arun(
url=site_url,
cache_mode=CacheMode.BYPASS,
session_id="session_captcha_test"
)
js_code = """
const originalFetch = window.fetch;
window.fetch = function(...args) {
if (typeof args[0] === \'string\' && args[0].includes(\'/recaptcha-v3-verify.php\')) {
const url = new URL(args[0], window.location.origin);
url.searchParams.set('action', '"+ token +"');
args[0] = url.toString();
document.querySelector('.token').innerHTML = "fetch('/recaptcha-v3-verify.php?action=examples/v3scores&token="+token+")";
console.log('Fetch URL hooked:', args[0]);
}
return originalFetch.apply(this, args);
};
"""
wait_condition = "() => {
return document.querySelector('.step3:not(.hidden)');
}"
run_config = CrawlerRunConfig(
cache_mode=CacheMode.BYPASS,
session_id="session_captcha_test",
js_code=js_code,
js_only=True,
wait_for=f"js:{wait_condition}"
)
result_next = await crawler.arun(
url=site_url,
config=run_config,
)
print(result_next.markdown)
if __name__ == "__main__":
asyncio.run(main())如果 v3 验证码无效,请通过扩展程序获取 JSON 配置并发送给我们的支持团队以改进验证码评分:解决 reCAPTCHA v2、invisible v2、v3、v3 Enterprise ≥0.9 分数.
5.3 解决 Cloudflare Turnstile
在开始解决 Cloudflare Turnstile 之前,请仔细阅读 CapSolver 的 Cloudflare Turnstile 文档 以确保了解创建任务时需要传递哪些参数以及如何获取这些值。接下来,我们将使用 Turnstile 演示 作为示例,演示如何解决 Cloudflare Turnstile。
解决 Turnstile 后,令牌将被注入名为 cf-turnstile-response 的输入元素中。因此,我们的 js_code 也需要模拟此操作。在继续下一步操作时,例如点击登录,此令牌将自动携带以进行验证。
python
import asyncio
import capsolver
from crawl4ai import *
# TODO: 设置您的配置
api_key = "CAP-xxxxxxxxxxxxxxxxxxxxx" # 您的 CapSolver API 密钥
site_key = "0x4AAAAAAAGlwMzq_9z6S9Mh" # 您的目标网站的 site key
site_url = "https://clifford.io/demo/cloudflare-turnstile" # 您的目标网站的页面 URL
captcha_type = "AntiTurnstileTaskProxyLess" # 您的目标验证码类型
capsolver.api_key = api_key
async def main():
browser_config = BrowserConfig(
verbose=True,
headless=False,
use_persistent_context=True,
)
async with AsyncWebCrawler(config=browser_config) as crawler:
await crawler.arun(
url=site_url,
cache_mode=CacheMode.BYPASS,
session_id="session_captcha_test"
)
# 使用 CapSolver SDK 获取 Turnstile 验证码
solution = capsolver.solve({
"type": captcha_type,
"websiteURL": site_url,
"websiteKey": site_key,
})
token = solution["token"]
print("Turnstile 验证码:", token)
js_code = """
document.querySelector('input[name="cf-turnstile-response"]').value = '"""+token+""";
document.querySelector('button[type="submit"]').click();
"""
wait_condition = """() => {
const items = document.querySelectorAll('h1');
return items.length === 0;
}"""
run_config = CrawlerRunConfig(
cache_mode=CacheMode.BYPASS,
session_id="session_captcha_test",
js_code=js_code,
js_only=True,
wait_for=f"js:{wait_condition}"
)
result_next = await crawler.arun(
url=site_url,
config=run_config,
)
print(result_next.markdown)
if __name__ == "__main__":
asyncio.run(main())5.4 解决 Cloudflare Challenge
Cloudflare Challenge 通常需要更复杂的处理,包括匹配浏览器指纹和 User-Agent。CapSolver 提供了 AntiCloudflareTask 类型来解决此类挑战。在解决 Cloudflare Challenge 之前,请查阅 CapSolver 的 Cloudflare Challenge 文档 以了解创建任务时所需的参数以及如何获取它们。
注意事项:
- 浏览器版本、平台和 userAgent 必须与 CapSolver 使用的版本一致。
- userAgent 必须与版本和平台一致。
python
import asyncio
import time
import capsolver
from crawl4ai import *
# TODO: 设置您的配置
api_key = "CAP-XXX" # 您的 CapSolver API 密钥
site_url = "https://www.tempo.co/hukum/polisi-diduga-salah-tangkap-pelajar-di-magelang-yang-dituduh-perusuh-demo-2070572" # 您的目标网站的页面 URL
captcha_type = "AntiCloudflareTask" # 您的目标验证码类型
api_proxy = "http://127.0.0.1:13120"
capsolver.api_key = api_key
user_data_dir = "./crawl4ai_/browser-profile/Default1493"
# 或者
cdp_url = "ws://localhost:xxxx"
async def main():
print("解决验证码开始")
start_time = time.time()
# 使用 CapSolver SDK 获取 Cloudflare 验证码
solution = capsolver.solve({
"type": captcha_type,
"websiteURL": site_url,
"proxy": api_proxy,
"userAgent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36"
})
token_time = time.time()
print(f"解决验证码耗时: {token_time - start_time:.2f} 秒")
# 设置 cookies
cookies = solution.get("cookies", [])
if isinstance(cookies, dict):
cookies_array = []
for name, value in cookies.items():
cookies_array.append({
"name": name,
"value": value,
"url": site_url,
})
cookies = cookies_array
elif not isinstance(cookies, list):
cookies = []
token = solution["token"]
print("Challenge 验证码:", token)
browser_config = BrowserConfig(
verbose=True,
headless=False,
use_persistent_context=True,
user_data_dir=user_data_dir,
# cdp_url=cdp_url,
user_agent=solution["userAgent"],
cookies=cookies,
)
async with AsyncWebCrawler(config=browser_config) as crawler:
result = await crawler.arun(
url=site_url,
cache_mode=CacheMode.BYPASS,
session_id="session_captcha_test"
)
print(result.markdown[:500])
if __name__ == "__main__":
asyncio.run(main())5.5 解决 AWS WAF
AWS WAF 是一种 Web 应用程序防火墙,通常通过设置特定的 Cookie 来验证请求。有关处理 AWS WAF 的更多信息,请参考我们的 AWS WAF 文档,以确保了解创建任务时需要提交哪些参数以及如何获取这些值。解决 AWS WAF 的关键是获取 CapSolver 返回的 aws-waf-token Cookie。
示例代码分析:
代码通过 CapSolver 获取 aws-waf-token,然后使用 js_code 将其设置为页面 Cookie 并刷新页面。刷新后,Crawl4AI 将使用正确的 Cookie 访问页面,从而绕过 AWS WAF 检测。
python
import asyncio
import capsolver
from crawl4ai import *
# TODO: 设置您的配置
api_key = "CAP-xxxxxxxxxxxxxxxxxxxxx" # 您的 CapSolver API 密钥
site_url = "https://nft.porsche.com/onboarding@6" # 您的目标网站的页面 URL
cookie_domain = ".nft.porsche.com" # 您希望应用 cookie 的域名
captcha_type = "AntiAwsWafTaskProxyLess" # 您的目标验证码类型
capsolver.api_key = api_key
async def main():
browser_config = BrowserConfig(
verbose=True,
headless=False,
use_persistent_context=True,
)
async with AsyncWebCrawler(config=browser_config) as crawler:
await crawler.arun(
url=site_url,
cache_mode=CacheMode.BYPASS,
session_id="session_captcha_test"
)
# 使用 CapSolver SDK 获取 AWS WAF cookie
solution = capsolver.solve({
"type": captcha_type,
"websiteURL": site_url,
})
cookie = solution["cookie"]
print("AWS WAF cookie:", cookie)
js_code = """
document.cookie = 'aws-waf-token=""" + cookie + """;domain=""" + cookie_domain + """;path=/';
location.reload();
"""
wait_condition = """() => {
return document.title === '加入保时捷在 Web3 的旅程';
}"""
run_config = CrawlerRunConfig(
cache_mode=CacheMode.BYPASS,
session_id="session_captcha_test",
js_code=js_code,
js_only=True,
wait_for=f"js:{wait_condition}"
)
result_next = await crawler.arun(
url=site_url,
config=run_config,
)
print(result_next.markdown)
if __name__ == "__main__":
asyncio.run(main())6. 如何通过 CapSolver 扩展进行集成
将浏览器扩展与 crawl4ai 集成需要指定浏览器的启动目录,然后安装扩展以解决验证码。您可以选择让扩展自动解决验证码,或者使用 js_code 进行主动解决。一般步骤如下:
- 通过指定
user_data_dir启动浏览器。 - 安装扩展:访问
chrome://extensions,在右上角点击“开发者模式”,然后选择“加载解压的扩展程序”并选择本地扩展项目目录。 - 访问 CapSolver 扩展页面并配置 API 密钥;或者在扩展项目中的
/CapSolver/assets/config.js中直接配置apiKey。
config.js参数说明:
useCapsolver: 是否自动使用 CapSolver 检测和解决验证码。manualSolving: 是否手动触发验证码解决。useProxy: 是否配置代理。enabledForBlacklistControl: 是否启用黑名单控制。- ...
- 访问包含验证码的页面。
- 等待扩展自动处理 / 使用
js_code在适当的时候解决验证码。 - 使用 crawl4ai 继续其他操作。
以下示例将展示如何通过浏览器扩展集成解决 reCAPTCHA v2/v3、Cloudflare Turnstile、AWS WAF。
6.1 解决 reCAPTCHA v2
在解决 reCAPTCHA v2 之前,请确保已正确配置扩展。接下来,我们将使用演示 API 作为示例,演示如何解决 reCAPTCHA v2。
解决 reCAPTCHA 后,当继续下一步操作时,例如点击登录,验证将自动进行。
python
import asyncio
import time
from crawl4ai import *
# TODO: 设置您的配置
user_data_dir = "/browser-profile/Default1"
browser_config = BrowserConfig(
verbose=True,
headless=False,
user_data_dir=user_data_dir,
use_persistent_context=True,
proxy="http://127.0.0.1:13120",
)
async def main():
async with AsyncWebCrawler(config=browser_config) as crawler:
result_initial = await crawler.arun(
url="https://recaptcha-demo.appspot.com/recaptcha-v2-checkbox.php",
cache_mode=CacheMode.BYPASS,
session_id="session_captcha_test"
)
# 后续操作
time.sleep(300)
if __name__ == "__main__":
asyncio.run(main())如果您需要主动选择何时解决验证码,请使用以下代码:
- 注意:在扩展页面上点击“手动解决”。
您需要将扩展的 manualSolving 参数配置为 true。否则,扩展会自动触发验证码解决。
python
import asyncio
import time
from crawl4ai import *
# TODO: 设置您的配置
user_data_dir = "/browser-profile/Default1"
browser_config = BrowserConfig(
verbose=True,
headless=False,
user_data_dir=user_data_dir,
use_persistent_context=True,
proxy="http://127.0.0.1:13120",
)
async def main():
async with AsyncWebCrawler(config=browser_config) as crawler:
result_initial = await crawler.arun(
url="https://recaptcha-demo.appspot.com/recaptcha-v2-checkbox.php",
cache_mode=CacheMode.BYPASS,
session_id="session_captcha_test"
)
# 后续操作
time.sleep(6)
js_code = """
let solverButton = document.querySelector('#capsolver-solver-tip-button');
if (solverButton) {
// 点击事件
const clickEvent = new MouseEvent('click', {
bubbles: true,
cancelable: true,
view: window
});
solverButton.dispatchEvent(clickEvent);
}
"""
print(js_code)
run_config = CrawlerRunConfig(
cache_mode=CacheMode.BYPASS,
session_id="session_captcha_test",
js_code=js_code,
js_only=True,
)
result_next = await crawler.arun(
url="https://recaptcha-demo.appspot.com/recaptcha-v2-checkbox.php",
config=run_config
)
print("JS 执行结果:", result_next.js_execution_result)
time.sleep(300)
if __name__ == "__main__":
asyncio.run(main())6.2 解决 reCAPTCHA v3
在解决 reCAPTCHA v3 之前,请确保已正确配置扩展。接下来,我们将使用演示 API 作为示例,演示如何解决 reCAPTCHA v3。
解决 reCAPTCHA 后,当继续下一步操作时,例如点击登录,验证将自动进行。
- 建议通过扩展程序自动解决 reCAPTCHA v3,通常在访问网站时触发。
python
import asyncio
import time
from crawl4ai import *
# TODO: 设置您的配置
user_data_dir = "/browser-profile/Default1"
browser_config = BrowserConfig(
verbose=True,
headless=False,
user_data_dir=user_data_dir,
use_persistent_context=True,
proxy="http://127.0.0.1:13120",
)
async def main():
async with AsyncWebCrawler(config=browser_config) as crawler:
result_initial = await crawler.arun(
url="https://recaptcha-demo.appspot.com/recaptcha-v2-checkbox.php",
cache_mode=CacheMode.BYPASS,
session_id="session_captcha_test"
)
# 稍后做些事情
time.sleep(300)
if __name__ == "__main__":
asyncio.run(main())6.3. 解决 Cloudflare Turnstile
在解决 Cloudflare Turnstile 之前,请确保已正确配置扩展程序。接下来,我们将使用 Turnstile 演示 作为示例,演示如何解决 Cloudflare Turnstile。
解决 Turnstile 后,会将一个令牌注入名为 cf-turnstile-response 的输入元素中。在继续下一步(如点击登录)时,此令牌会自动携带以进行验证。
python
import asyncio
import time
from crawl4ai import *
# TODO: 设置您的配置
user_data_dir = "/browser-profile/Default1"
browser_config = BrowserConfig(
verbose=True,
headless=False,
user_data_dir=user_data_dir,
use_persistent_context=True,
proxy="http://127.0.0.1:13120",
)
async def main():
async with AsyncWebCrawler(config=browser_config) as crawler:
result_initial = await crawler.arun(
url="https://recaptcha-demo.appspot.com/recaptcha-v2-checkbox.php",
cache_mode=CacheMode.BYPASS,
session_id="session_captcha_test"
)
# 稍后做些事情
time.sleep(300)
if __name__ == "__main__":
asyncio.run(main())6.4. 解决 AWS WAF
在解决 AWS WAF 之前,请确保 CapSolver 扩展程序已正确配置。在此示例中,我们将使用 AWS WAF 演示 来演示该过程。
一旦解决 AWS WAF,将获得一个名为 aws-waf-token 的 cookie。此 cookie 会在后续操作中自动携带以进行验证。
python
import asyncio
import time
from crawl4ai import *
# TODO: 设置您的配置
user_data_dir = "/browser-profile/Default1"
browser_config = BrowserConfig(
verbose=True,
headless=False,
user_data_dir=user_data_dir,
use_persistent_context=True,
proxy="http://127.0.0.1:13120",
)
async def main():
async with AsyncWebCrawler(config=browser_config) as crawler:
result_initial = await crawler.arun(
url="https://nft.porsche.com/onboarding@6",
cache_mode=CacheMode.BYPASS,
session_id="session_captcha_test"
)
# 稍后做些事情
time.sleep(300)
if __name__ == "__main__":
asyncio.run(main())如果您需要主动选择何时解决验证码,请使用以下代码:
- 注意:在扩展程序页面上点击“手动解决”。
您需要将扩展程序的 manualSolving 参数设置为 true。否则,扩展程序会自动触发验证码解决。
python
import asyncio
import time
from crawl4ai import *
# TODO: 设置您的配置
user_data_dir = "/browser-profile/Default1"
browser_config = BrowserConfig(
verbose=True,
headless=False,
user_data_dir=user_data_dir,
use_persistent_context=True,
proxy="http://127.0.0.1:13120",
)
async def main():
async with AsyncWebCrawler(config=browser_config) as crawler:
result_initial = await crawler.arun(
url="https://nft.porsche.com/onboarding@6",
cache_mode=CacheMode.BYPASS,
session_id="session_captcha_test"
)
# 稍后做些事情
time.sleep(6)
js_code = """
let solverButton = document.querySelector(\'#capsolver-solver-tip-button\');
if (solverButton) {
// 点击事件
const clickEvent = new MouseEvent(\'click\', {
bubbles: true,
cancelable: true,
view: window
});
solverButton.dispatchEvent(clickEvent);
}
"""
print(js_code)
run_config = CrawlerRunConfig(
cache_mode=CacheMode.BYPASS,
session_id="session_captcha_test",
js_code=js_code,
js_only=True,
)
result_next = await crawler.arun(
url="https://nft.porsche.com/onboarding@6",
config=run_config
)
print("JS 执行结果:", result_next.js_execution_result)
time.sleep(300)
if __name__ == "__main__":
asyncio.run(main())7. 结论
Crawl4AI 与 CapSolver 的官方合作标志着网页数据抓取领域的一个重要里程碑。通过将 Crawl4AI 的高效爬取能力与 CapSolver 的强大验证码解决服务相结合,开发者现在可以构建更稳定、高效和健壮的自动化爬虫系统。
无论处理复杂的动态内容还是各种反机器人机制,这种集成解决方案都表现出色且灵活。API 集成提供了细粒度的控制和更高的准确性,而浏览器扩展集成简化了配置过程,满足不同场景的需求。
7.1. 常见问题
Q1: Crawl4AI 和 CapSolver 集成是什么,它是如何解决验证码的?
A1: 该集成将 Crawl4AI 的先进网页爬取功能与 CapSolver 的自动化验证码解决功能相结合。它可以绕过 reCAPTCHA v2/v3、Cloudflare Turnstile 和 AWS WAF 等验证码,实现无需人工干预的不间断、高效的网页数据提取。
Q2: 对网页抓取的主要优势是什么?
A2: 主要优势包括自动化处理验证码、更快更可靠的爬取、对反机器人机制的更强鲁棒性,以及通过减少人工验证码解决来降低运营成本。
Q3: 它如何处理不同的验证码类型?
A3: 通过 API 和浏览器扩展方法,它可以解决:
- reCAPTCHA v2: 将令牌注入页面
- reCAPTCHA v3: 使用 fetch 钩子动态替换令牌
- Cloudflare Turnstile: 将令牌注入输入字段
- AWS WAF: 获取有效 cookie
这确保了对各种挑战的全面绕过。
Q4: Crawl4AI 的核心功能是什么,用于 AI 和数据提取?
A4: Crawl4AI 提供结构化的 Markdown 内容用于 AI 代理,具有代理和会话管理的高级浏览器控制,自适应高性能爬取,避免机器人检测的隐身模式,以及用于登录会话的身份感知爬取。
7.2. 文档
合规声明: 本博客提供的信息仅供参考。CapSolver 致力于遵守所有适用的法律和法规。严禁以非法、欺诈或滥用活动使用 CapSolver 网络,任何此类行为将受到调查。我们的验证码解决方案在确保 100% 合规的同时,帮助解决公共数据爬取过程中的验证码难题。我们鼓励负责任地使用我们的服务。如需更多信息,请访问我们的服务条款和隐私政策。
更多

如何在Crawl4AI中通过CapSolver集成解决验证码
与Crawl4AI & CapSolver的无缝网络爬取:自动化验证码解决方案、提升的效率以及强大的AI数据提取。
Ethan Collins
26-Sep-2025

PIA S5 Proxy:全球領先的SOCKS5住宅代理助妳輕鬆隱藏IP
PIA S5 代理是全球领先的 SOCKS5 住宅代理,帮助用户轻松隐藏 IP,保护网络隐私,并提供安全的在线体验。
Ethan Collins
08-Oct-2024

VMLogin:多账号登录防关联浏览器
在这篇文章,我们将会向你展示什么是VMLogin浏览器以及他们所提供的服务。

Emma Foster
18-Mar-2024

MuLogin 指纹浏览器:多平台多账户管理
在这篇文章,我们将会向你展示什么是MuLogin 指纹浏览器以及他们所提供的服务。
Emma Foster
18-Mar-2024

火豹浏览器:专业的跨境电商平台安全管家
在这篇文章,我们将会向你展示什么是火豹浏览器以及他们所提供的服务。
Emma Foster
23-Jan-2024

比特浏览器:多开账号,防封号,防关联指纹浏览器
在这篇文章,我们将会向你展示什么是比特浏览器以及他们所提供的服务
Emma Foster
19-Jan-2024