Как начать веб-скрейпинг в R: Полное руководство на 2025 год
Как начать веб-скрейпинг в R: Полное руководство на 2025 год
Nikolai Smirnov
Software Development Lead
26-Nov-2024
Бывают ли моменты, когда вам интересно, как специалисты по обработке данных собирают большие объемы онлайн-данных для исследований, маркетинга и анализа? Веб-скрейпинг в R — это мощный навык, который может преобразовать онлайн-контент в ценные наборы данных, позволяя принимать решения на основе данных и получать более глубокие знания. Итак, что делает веб-скрейпинг сложным, и как может помочь R? В этом руководстве мы рассмотрим настройку вашей среды R, извлечение данных с веб-страниц, обработку более сложных сценариев, таких как динамический контент, и завершим описание лучших практик для поддержания этических и правовых норм.
Почему стоит выбрать R?
R — это язык и среда, используемые в первую очередь для статистического анализа и визуализации данных. Первоначально популярный среди статистиков в академических кругах, R расширил свою пользовательскую базу до исследователей в различных областях. С ростом больших данных специалисты из вычислительной и инженерной сфер внесли значительный вклад в улучшение вычислительного движка, производительности и экосистемы R, способствуя его развитию.
В качестве интегрированного инструмента для статистического анализа и графического отображения R универсален и бесшовно работает в UNIX, Windows и macOS. Он имеет надежную, удобную систему справки и предназначен для работы с данными, предлагая богатый набор библиотек, ориентированных на данные, идеально подходящих для таких задач, как веб-скрейпинг.
Однако независимо от языка программирования, который вы используете для веб-скрейпинга, важно соблюдать протокол robots.txt веб-сайтов. Этот файл, расположенный в корневом каталоге большинства веб-сайтов, указывает, какие страницы можно и нельзя сканировать. Соблюдение этого протокола помогает избежать ненужных споров с владельцами веб-сайтов.
Настройка среды R
Прежде чем использовать R для веб-скрейпинга, убедитесь, что у вас правильно настроена среда R:
Загрузка и установка R:
Посетите официальный веб-сайт проекта R и загрузите соответствующий установочный пакет для вашей операционной системы.
Выбор IDE для R:
Выберите среду разработки для запуска кода R:
PyCharm: Популярная IDE для Python, PyCharm также может поддерживать R через плагины. Посетите веб-сайт JetBrains, чтобы загрузить его.
RStudio: Специализированная IDE для R, которая обеспечивает бесшовный и интегрированный опыт. Посетите веб-сайт Posit, чтобы загрузить RStudio.
Если вы используете PyCharm:
Вам потребуется установить плагин R Language for IntelliJ, чтобы запускать код R в PyCharm.
Для этого руководства мы будем использовать PyCharm для создания нашего первого проекта веб-скрейпинга R. Начните с открытия PyCharm и создания нового проекта.
Нажмите «Создать», и PyCharm инициализирует ваш проект R. Он автоматически создаст пустой файл main.R. Справа и внизу интерфейса вы найдете вкладки R Tools и R Console соответственно. Эти вкладки позволяют управлять пакетами R и получать доступ к оболочке R, как показано на рисунке ниже:
Использование R для извлечения данных
Возьмем первое упражнение из ScrapingClub в качестве примера, чтобы продемонстрировать, как использовать R для извлечения изображений продуктов, названий, цен и описаний:
1. Установка rvest
rvest — это пакет R, предназначенный для помощи в веб-скрейпинге. Он упрощает общие задачи веб-скрейпинга и бесшовно работает с пакетом magrittr, предоставляя простой в использовании конвейер для извлечения данных. Пакет вдохновлен такими библиотеками, как Beautiful Soup и RoboBrowser.
Чтобы установить rvest в PyCharm, используйте R Console, расположенную внизу интерфейса. Введите следующую команду:
RCopy
install.packages("rvest")
Перед началом установки PyCharm предложит вам выбрать зеркало CRAN (источник пакетов). Выберите ближайшее к вашему местоположению для более быстрой загрузки. После установки вы можете начать скрейпинг!
2. Доступ к HTML-странице
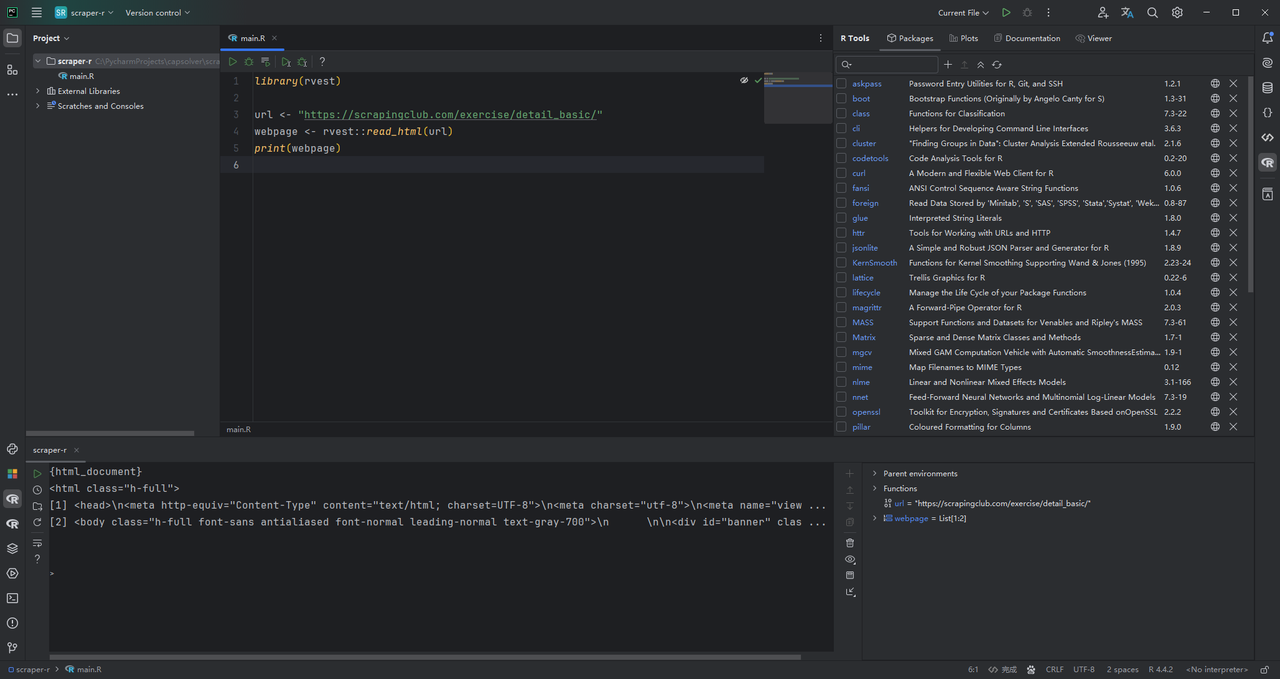
Пакет rvest предоставляет функцию read_html(), которая извлекает HTML-контент веб-страницы, если задан ее URL-адрес. Вот как вы можете использовать ее для получения HTML целевого веб-сайта:
Запуск этого кода выведет исходный код HTML страницы в R Console, что даст вам четкое представление о структуре веб-страницы. Это основа для извлечения определенных элементов, таких как сведения о продукте.
3. Разбор данных
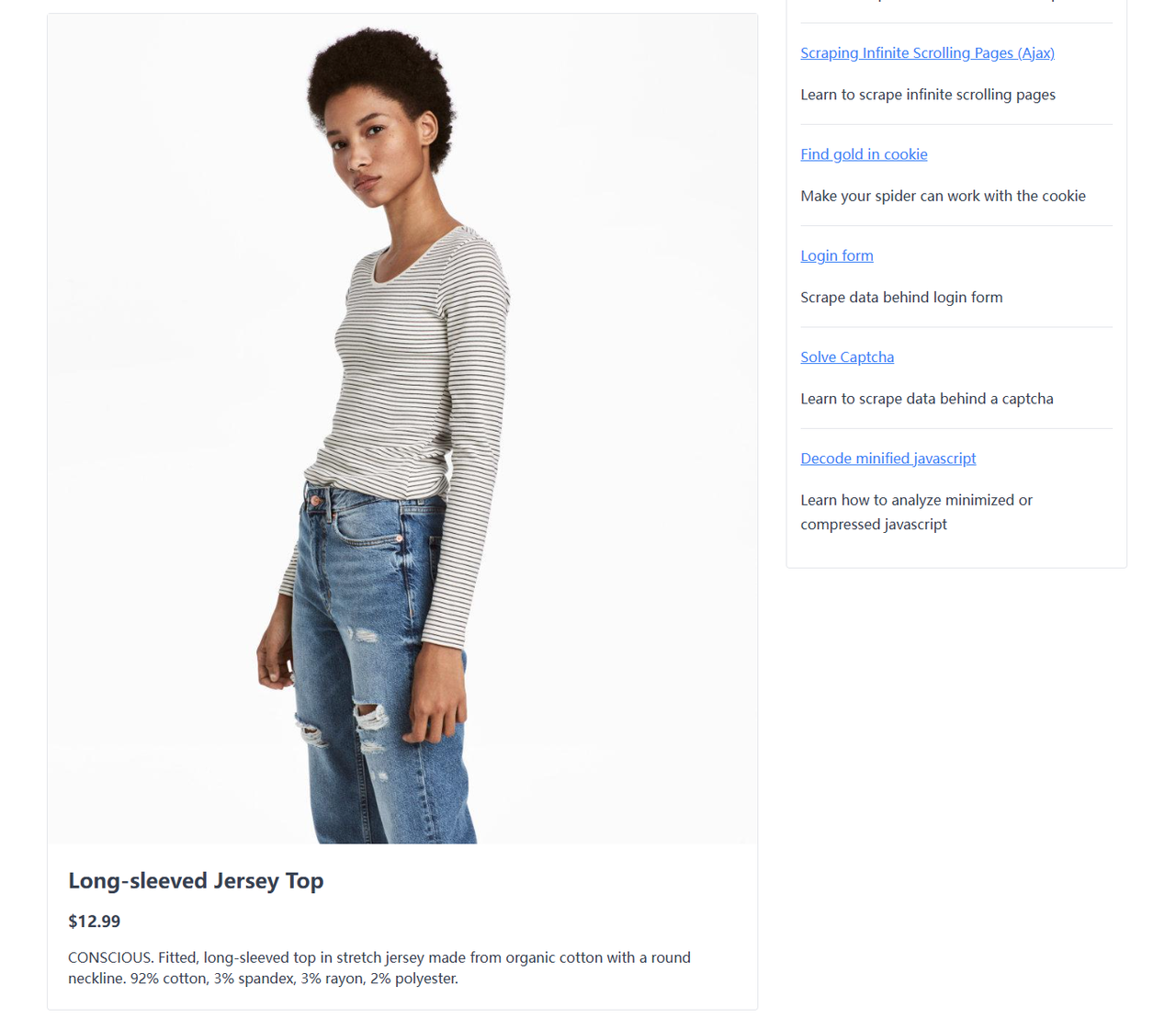
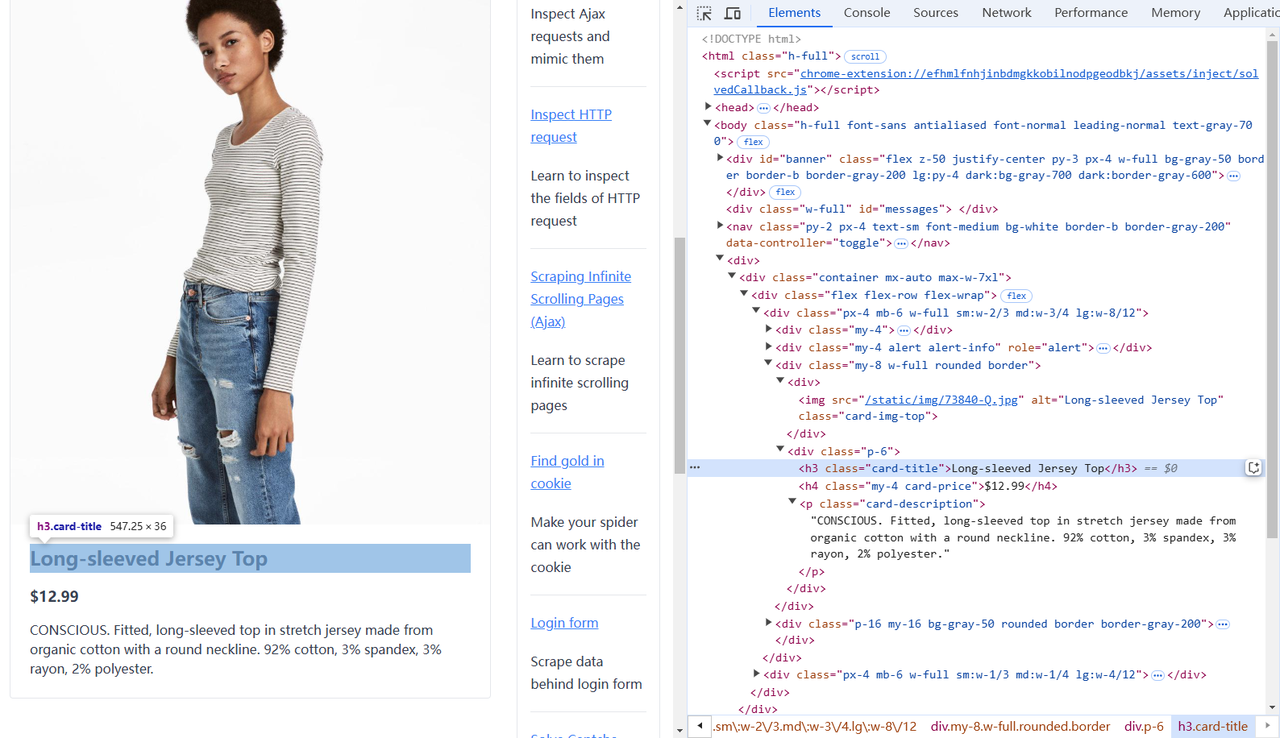
Чтобы извлечь определенные данные с веб-страницы, нам сначала нужно понять ее структуру. Используя инструменты разработчика вашего браузера, вы можете проверить элементы и определить, где находятся нужные данные. Вот разбивка целевых элементов на странице примера:
Изображение продукта: Находится в теге img с классом card-img-top.
Название продукта: Расположено внутри элемента <h3>.
Цена продукта: Содержится в элементе <h4>.
Описание продукта: Находится в теге <p> с классом card-description.
Пакет rvest в R предоставляет мощные инструменты для анализа и извлечения контента из HTML-документов. Вот некоторые ключевые функции, используемые для веб-скрейпинга:
html_nodes(): Выбирает все узлы (теги HTML) из документа, которые соответствуют указанному селектору CSS. Это позволяет эффективно фильтровать контент с помощью синтаксиса, подобного CSS.
html_attr(): Извлекает значение указанного атрибута из выбранных узлов HTML. Например, вы можете получить атрибут src для изображений или href для ссылок.
html_text(): Извлекает простой текстовый контент внутри выбранных узлов HTML, игнорируя теги HTML.
Вот как вы можете использовать эти функции для извлечения данных со страницы примера:
RCopy
library(rvest)
# URL целевой веб-страницы
url <- "https://scrapingclub.com/exercise/detail_basic/"
webpage <- rvest::read_html(url)
# Извлечение данных
img_src <- webpage %>% html_nodes("img.card-img-top") %>% html_attr("src") # Источник изображения
title <- webpage %>% html_nodes("h3") %>% html_text() # Название продукта
price <- webpage %>% html_nodes("h4") %>% html_text() # Цена продукта
description <- webpage %>% html_nodes("p.card-description") %>% html_text() # Описание продукта
# Отображение извлеченных данных
print(img_src)
print(title)
print(price)
print(description)
Пояснение кода
Чтение HTML: Функция read_html() извлекает всю HTML-структуру целевой веб-страницы.
Извлечение данных: Используя селекторы CSS с помощью html_nodes(), вы можете выбирать определенные элементы, такие как изображения, названия и описания.
Получение атрибутов/текста: Функция html_attr() извлекает значения атрибутов, такие как src для изображений, а html_text() извлекает текстовый контент внутри тегов.
Пример вывода
При запуске приведенного выше кода извлеченные данные будут отображаться в вашей консоли R. Например:
URL изображения: Путь к изображению продукта, например /images/example.jpg.
Название: Название продукта, например "Образец продукта".
Цена: Информация о цене, например "$20.99".
Описание: Описание продукта, например "Это высококачественный товар.".
Это позволяет эффективно собирать структурированные данные с веб-страницы, готовые для дальнейшего анализа или хранения.
Предварительный просмотр результата
После запуска скрипта вы должны увидеть извлеченный контент в вашей консоли R, как показано ниже:
Используя rvest, вы можете автоматизировать процесс веб-скрейпинга для различных задач со структурированными данными, обеспечивая чистые и пригодные для использования результаты.
Проблемы веб-скрейпинга
В реальных сценариях веб-скрейпинга процесс редко бывает таким простым, как демонстрация в этой статье. Вы часто будете сталкиваться с различными проблемами ботов, такими как широко используемый reCAPTCHA и аналогичные системы.
Эти системы предназначены для проверки того, являются ли запросы законными, путем реализации таких мер, как:
Проверка заголовков запросов: Проверка того, соответствуют ли ваши HTTP-заголовки стандартным шаблонам.
Проверки отпечатков браузера: Обеспечение того, чтобы ваш браузер или инструмент для скрейпинга имитировали поведение реального пользователя.
Оценка риска IP-адреса: Определение того, помечен ли ваш IP-адрес как подозрительный.
Сложное шифрование JavaScript: Требуется выполнение сложных вычислений или использование зашифрованных параметров для продолжения.
Сложное распознавание изображений или текста: Принуждение решателей к правильному распознаванию элементов из изображений CAPTCHA.
Все эти меры могут значительно затруднить ваши усилия по скрейпингу. Однако не стоит беспокоиться. Каждую из этих проблем ботов можно эффективно решить с помощью CapSolver.
Почему CapSolver?
CapSolver использует технологию Auto Web Unblock, основанную на искусственном интеллекте, способную решать даже самые сложные задачи CAPTCHA всего за несколько секунд. Она автоматизирует такие задачи, как декодирование зашифрованного JavaScript, генерация действительных отпечатков браузера и решение сложных головоломок CAPTCHA, обеспечивая бесперебойный сбор данных.
Запросите свой бонусный код для лучших решений captcha; CapSolver: WEBS. После его активации вы получите дополнительный бонус в 5% после каждой подзарядки, без ограничений
Простая интеграция
CapSolver предоставляет SDK на нескольких языках программирования, что позволяет легко интегрировать его функции в ваш проект. Независимо от того, используете ли вы Python, R, Node.js или другие инструменты, CapSolver упрощает процесс внедрения.
Документация и поддержка
Официальная документация CapSolver содержит подробные руководства и примеры, которые помогут вам начать работу. Там вы можете изучить дополнительные возможности и параметры конфигурации, обеспечивающие плавный и эффективный опыт скрейпинга.
Заключение
Веб-скрейпинг с помощью R открывает множество возможностей для сбора и анализа данных, превращая неструктурированный онлайн-контент в пригодные для использования знания. С помощью таких инструментов, как rvest, для эффективного извлечения данных и таких сервисов, как CapSolver, для преодоления проблем скрейпинга, вы можете оптимизировать даже самые сложные проекты скрейпинга.
Однако всегда помните о важности этичных методов скрейпинга. Соблюдение рекомендаций веб-сайтов, уважение файла robots.txt и обеспечение соответствия правовым нормам необходимы для поддержания ответственного и профессионального подхода к сбору данных.
Вооружившись знаниями и инструментами, описанными в этом руководстве, вы готовы начать свое путешествие в мир веб-скрейпинга с R. По мере приобретения опыта вы обнаружите способы обработки различных сценариев, расширите свой набор инструментов для скрейпинга и раскроете весь потенциал принятия решений на основе данных.
Дисклеймер о соблюдении: Информация, представленная в этом блоге, предназначена только для справочных целей. CapSolver обязуется соблюдать все применимые законы и нормы. Использование сети CapSolver для незаконной, мошеннической или злоупотребляющей деятельности строго запрещено и будет расследовано. Наши решения для распознавания капчи улучшают пользовательский опыт, обеспечивая 100% соблюдение при помощи в решении трудностей с капчей в процессе сбора общедоступных данных. Мы призываем к ответственному использованию наших услуг. Для получения дополнительной информации, пожалуйста, посетите наши Условия обслуживания и Политику конфиденциальности.